
이슈 리포트
뉴스 데이터에 관한 최신 정보 리포트를 제공하는 공간입니다.
![]()
저출산 보도, 지난 5년 동안 어떻게 변화해왔을까?
클러스터링 알고리즘을 활용한 저출산 이슈 보도 유형 분석
2023년 1분기의 합계출산율 0.81명에 이어 지난 2분기 통계 역시 0.7명을 기록하며 연말까지의 이번 년도 합계 출산율이 0.7 미만을 기록할 수도 있다는 의견이 제기되고 있습니다. 현 추세로는 2060년까지 국내 노인 인구가 전체 인구의 약 40%를 차지하는 상황까지 예상되는데요, 자연스레 언론에서도 인구 및 출산 이슈를 다양한 방식으로 소개해오고 있습니다. 오늘 저희가 BigKinds API를 활용하여 분석해 볼 주제는 이러한 미디어에 대한 메타적인 분석, 즉 “과연 지난 몇 년 간 국내 언론은 저출산이라는 주제를 어떠한 방식으로 다루어왔는가”입니다.
저희는 지난 2018년 6월부터 2023년 5월 사이에 작성된 ‘사회’ 섹션 기사들 중 제목과 본문 중 한 번이라도 ‘저출산’, ‘저출생’, ‘출산율’, ‘출생율’을 언급한 3,424건의 기사들을 수집했습니다. 1) 클릭 이들 기사의 비율을 집계한 결과, <그림1>과 같이 2018년 6월 이후 완만하게 감소 중이던 저출산 이슈 보도율은 2020년 하반기를 기점으로 반등하기 시작, 최근 6개월 새에 보도량이 매우 빠르게 증가한 경향을 확인할 수 있었습니다.
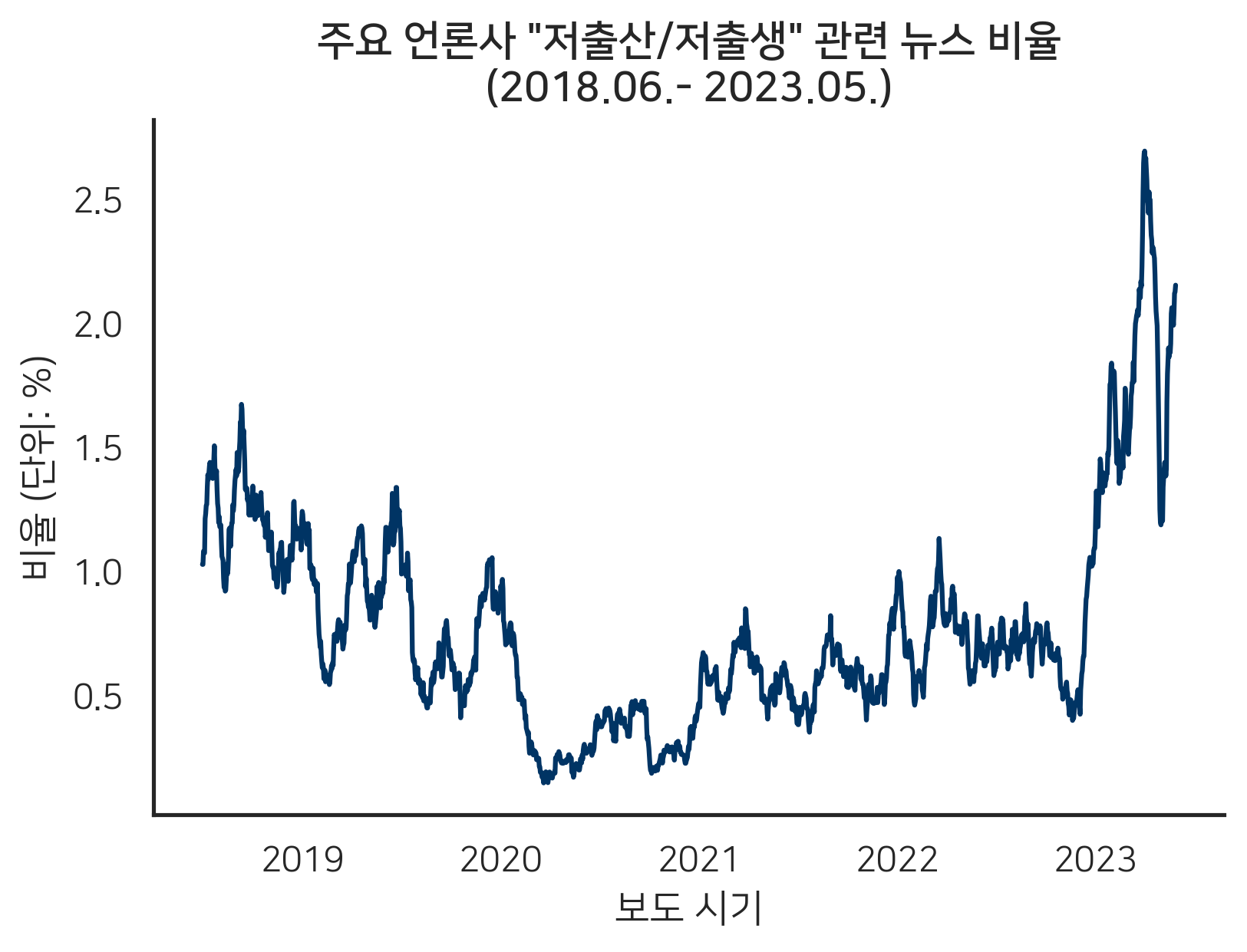
<그림1> 저출산·저출생 관련 기사 보도율
그렇다면 이들 3천여 건의 저출산 관련 기사들의 하위 토픽들을 기술적으로 어떻게 유형화해볼 수 있을까요? 바로 군집화(clustering) 알고리즘입니다. 자연어 모델(LM, Language Model)의 핵심인 임베딩(embedding)을 활용한다면, <그림2>에서 볼 수 있듯, 서로 다른 기사들을 좌표 평면의 점들로 표기할 수 있습니다. 각각의 점은 하나의 기사를 의미하고, 서로 가까이 있는 점(기사)들일수록 서로 내용적으로 유사하며, 반대로 그 거리가 멀수록 이질적임을 의미합니다. 한 데에 뭉쳐 있는 기사들을 우리는 하나의 군집(cluster)으로 간주할 수 있고, 각 군집은 저출산이라는 주제의 하위 토픽을 의미할 것입니다.
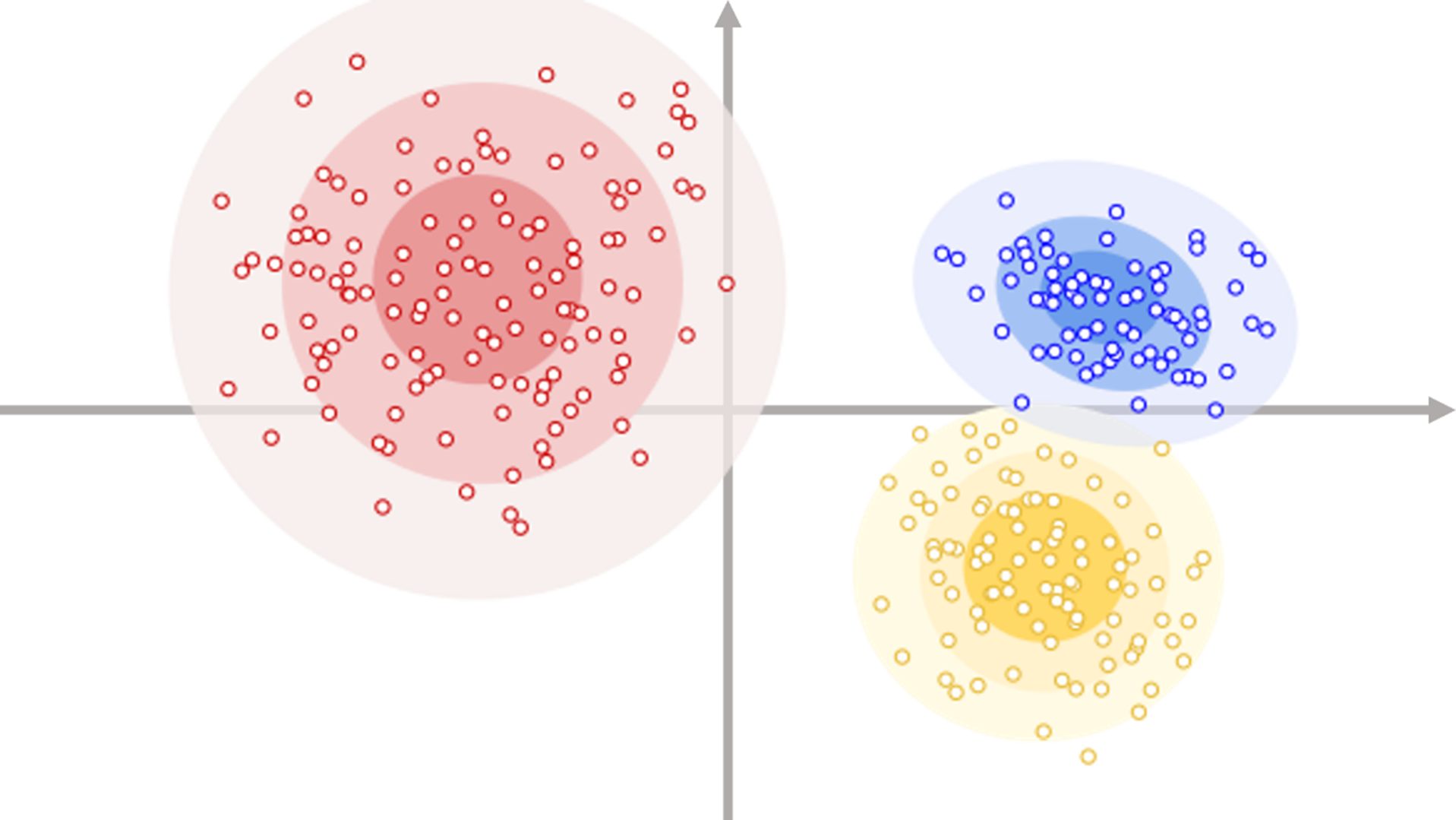
<그림2> 뉴스 클러스터링 예시 이미지
이러한 군집화 알고리즘을 저희의 데이터에 적용하자 2) 클릭 , 총 20가지의 저출산 관련 하위 토픽들을 확인할 수 있었습니다. 아래의 <그림3>은 이들 하위 토픽들이 각각 저출산 보도 내에서 차지하는 비율을 시각화한 그래프입니다. 고령화에 대한 일반론 다음으로 학령인구 감소 관련 논의가 두 번째로 보도율이 높은 점이 인상적입니다.
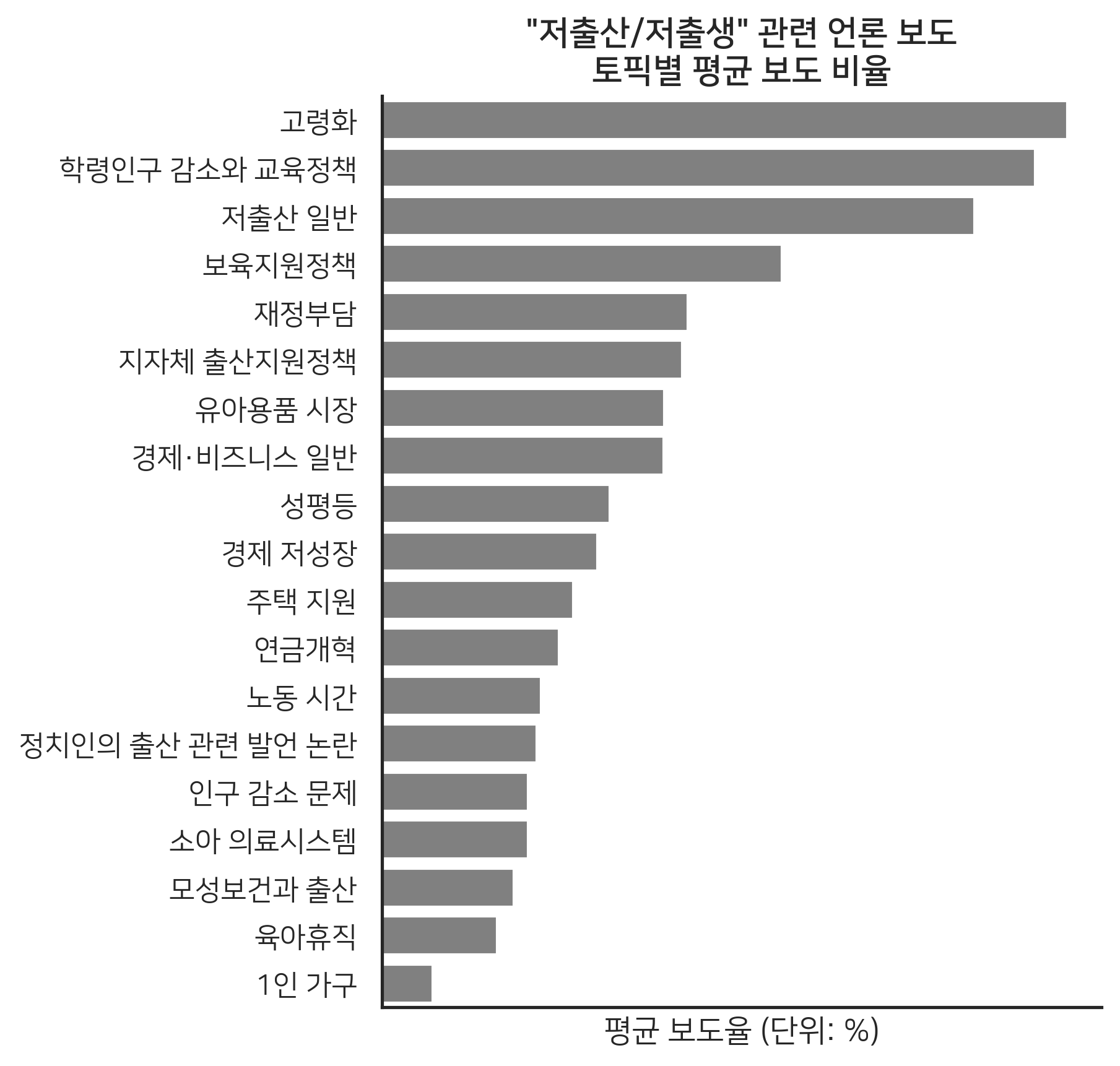
<그림3> 저출산·저출생 관련 하위 토픽별 보도율
저희는 여기서 각 토픽별로 시간의 흐름에 따른 변화까지 추적해 볼 수도 있습니다. <그림4>는 각 토픽별 주요 보도 시기를 시각화한 그래프입니다. X축의 ‘주요 보도 시기’를 보면 알 수 있듯, 그래프 상의 점이 좌측 맨 끝에 가까울수록 데이터의 첫 수집 시기인 2018년에 주로 위치해 오래된 토픽이고, 반대로 맨 오른쪽에 위치할수록 2023년에 주로 보도된 최신 토픽임을 의미합니다. 3) 클릭
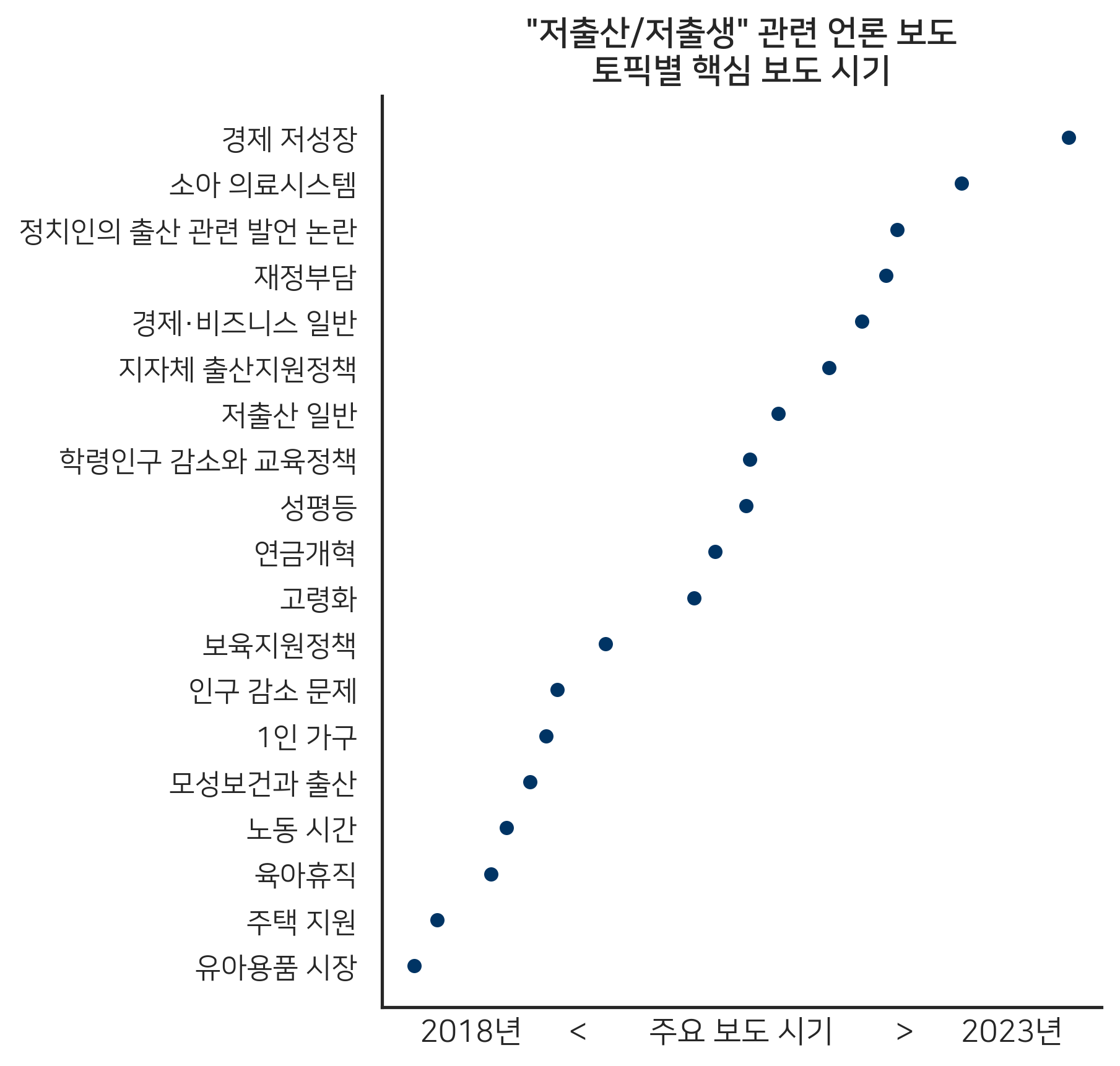
<그림4> 저출산·저출생 관련 하위 토픽별 핵심 보도 시기
최근 가장 강조되고 있는 세부 토픽은 ‘경제의 저성장’과 ‘소아 의료 시스템’이었습니다. 흥미롭게도 주택 지원이나 육아 휴직 제도 활성화, 노동시간 단축과 같은 저출산에 대한 정책적 대안들은 오히려 최근에는 크게 보도되고 있지 않았습니다. 이는 국내 언론들이 저출산 대응책을 논의하는 단계를 넘어, 인구 감소가 본격적으로 발생하기 시작하면, 이로 인해 사회가 받는 충격을 직접적으로 다루기 시작했음을 의미합니다.
그렇다면 실제 국민들의 출산 관련 의식과는 어떤 관계가 있을까요? 언론에서 저출산이라는 주제가 재현되는 방식에 대한 분석을 넘어 실제 사람들의 출산 의사를 알아보고자, 저희 언더스코어는 사회 조사 기업인 데이터스프링코리아에 의뢰해 전국민 1,500명을 대상으로 설문을 진행했습니다. 4) 클릭 아래의 <표 1>는 전체 설문 응답자들 중 만 40세 이하 미혼 인구 446명을 추출하여, 향후 출산 희망여부를 종속변수로 하여 회귀분석(regression) 5) 클릭 을 실시한 결과입니다. 흥미롭게도, 연령이나 단순 거주지, 학력 수준 등은 전혀 통계적으로 유의미한 영향이 없었습니다. 출산 의사에 가장 많은 영향을 주는 요소는 ‘성별’로, 여성보다 남성이 약 20%p 출산 의사가 더 높았습니다. (p<.001)
| 변수명 | 본인 소득 모델 | 가구 소득 모델 | 자산 모델 |
|---|---|---|---|
| (상수항) |
0.299*
(0.115) |
0.219
(0.153) |
0.418***
(0.124) |
| 성별 (남성=1) |
0.198***
(0.047) |
0.208***
(0.047) |
0.204***
(0.047) |
| 연령 |
0.002
(0.004) |
0.005
(0.004) |
0.003
(0.004) |
| 교육수준 (고학력=1) |
0.019
(0.058) |
0.018
(0.058) |
0.019
(0.058) |
| 거주지 (서울=1) |
-0.035
(0.062) |
-0.016
(0.061) |
-0.031
(0.061) |
| log(월 평균 본인 소득) (단위: 만) |
0.026**
(0.013) |
||
| log(월 평균 가구 소득) (단위: 만) |
0.018
(0.020) |
||
| log(가구 자산) (단위: 억) |
0.038*
(0.020) |
<표1> 기본 인구통계 변수 회귀분석 결과 6) 클릭
경제 수준의 경우 설문에서 ①본인 소득, ②가구 소득, ③본인 자산의 세 가지 변수를 통해 서로 다르게 측정했는데요, <표 1>에 작성된 바와 같이 다소 혼재된 결과가 관찰되었습니다. 7) 클릭 본인의 월 평균 소득이 100만원 씩 높아질수록 유의미하게 6%p (p<.05)씩 출산 희망률이 더 높아졌지만, 가구 소득의 경우 통계적인 상관성이 나타나지 않았고, 자산은 1,000만원 씩 늘어날수록 평균 7%p 씩 (p<.1) 응답값이 높아졌습니다. 회귀분석에 익숙하지 않은 분들은 <표 2> 8) 클릭 를 통해 해당 결과를 조금 더 직관적으로 이해 가능합니다. 월 평균 본인 소득 하위 30%인 사람들 중 향후 아이를 낳고 싶다고 한 비율은 48.8%였으나, 상위 30%는 77.1%을 기록해 28.3%p의 차이를 보이고 있습니다. 자산에 따른 출산 의사는 낮은 통계적 유의미성(p<.1)에서 예상할 수 있듯, 그 차이가 작았습니다. 자산 기준 하위 30%의 출산 희망률은 52.5%, 상위 30%는 63.1%를 기록해 10.6%p의 차이를 보였습니다.
| 소득/자산 분위 | 본인 소득 | 가구 소득 | 본인 자산 |
|---|---|---|---|
| 1분위 | 46.8% | 47.5% | 53.3% |
| 2분위 | 48.7% | 56.9% | 48.9% |
| 3분위 | 50.9% | 62.0% | 55.6% |
| 4분위 | 55.4% | 66.7% | 57.4% |
| 5분위 | 52.5% | 45.7% | 55.1% |
| 6분위 | 59.2% | 53.1% | 64.7% |
| 7분위 | 62.7% | 40.5% | 72.7% |
| 8분위 | 75.8% | 64.9% | 75.0% |
| 9분위 | 55.6% | 56.7% | 57.1% |
| 10분위 | 100% 9) 클릭 | 63.4% | 57.1% |
<표2> 소득/자산 분위별 출산 희망자 비율
설문 데이터 분석 결과를 정리하자면, 출산 의사 결정에 가장 큰 영향을 주는 것은 성별과 경제적 수준이었습니다. 물론 여전히 남은 질문들은 존재합니다. 왜 청년들의 거주 지역은 출산 의사에 영향을 주지 않는 것으로 나타났을까요? 혹 거주 방식이나 부동산과 같은, 어떠한 숨겨진 요인과의 교차 효과(interaction effect)가 있는 것은 아닐까요? 또, 가구 소득 및 자산이 본인의 소득에 비해 출산 의사에 그리 영향을 주지 못한 이유는 무엇일까요? 그리고 경제력이 출산 희망률에 미치는 영향은 시간에 따라 어떻게 변화해왔을까요? 2020년대에 이르러 저출산으로 인한 사회 변화가 본격적으로 시작되었기에 언론 입장에서 해당 이슈를 다루는 것은 꽤 자연스러운 현상입니다만, 어떠한 요인이 사람들의 출산 의사에 영향을 주는지에 대한 분석과 고민도 여전히 필요할 것 같습니다. ■
- 1) 최근, 대중적으로는 ‘출산’이 ‘출생’과 달리 여성을 수동적으로 간주하는 표현이라는 지적이 있어왔으나, 사회과학적으로는 출산율(fertility rate)과 출생률(birth rate)이 애초에 서로 다른 개념을 지칭함. 따라서 본 보고서에서 다루는 개념은 ‘저출산’이며, 이에 ‘출생’보다는 ‘출산’이라는 표현을 본문에서 주로 사용함. 단, 데이터 전처리 과정 및 도표 제목에서는 ‘저출산’과 ‘저출생’ 개념을 함께 활용하였음.
- 2) SBERT 임베딩 및 K-means 알고리즘을 활용
- 3) 해당 그래프는 ‘상대적인’ 주요 보도 시기를 데이터 수집 첫 시점인 2018년과 2023년 사이에서 시각화한 것. 각 점은 ”주요 보도 시기”이지, 해당 시기에만 보도가 이루어졌다는 것을 의미하지 않음에 유의
- 4) 조사기간 : 2022.05.04.-2022.05.09. / 조사대상 : 성별·연령·지역별 인구비례를 고려한 표본 만 18~69세 1,500명 / 조사방법 : 온라인 조사 / 표본오차 : 95% 신뢰수준에 ±2.5%
- 5) LPM(Linear Probability Model)
- 6) 로그 변환 시 소득/자산이 0인 응답자들의 처리를 위해 하한값으로서 전자의 경우 월 소득 10만원을, 후자의 경우 자산 1,000만원을 설정함
- 7) 본인 소득 / 가구 소득 / 본인 자산의 세 변수를 단일한 모델에 포함시킬 경우
- 8) 단, <표 2>는 다른 변수를 통제하지 않은 단순 기술통계이기에, 해당 소득/자산의 한계 효과(marginal effect)를 보여주지는 않는 것에 유의
- 9) 10분위 구분의 특성 상, 해당 구간의 응답자 수는 8명으로 매우 적다는 사실에 유의



회원가입

